
Voltorb Flip: Overanalyzing a Minigame in Pokemon HeartGold and Soul Silver -- Part 2
Prior Art, some Python code, and a Heuristic Algorithm that beats the previous literature!

This post is Part 2 of a four-part series on Voltorb Flip, a minigame found in Pokemon HeartGold and SoulSilver. If you haven’t read Part 1 of my series overanalyzing Voltorb Flip, it can be found here.
In the last post, we took deterministic logic as far as we could. We found that using two (and a half) simple rules we could completely solve some boards and greatly restrict the possible configurations of others. Unfortunately, on most boards we’re reduced to guessing.

Prior Art
How do we guess well? It’s a very common question, and surprisingly difficult to answer. Jaff et al. in their seminal paper on Voltorb Flip analyze four potential algorithms we could choose:
BOGOFlip: completely random guessing
MinRisk: chooses the tile least likely to contain a Voltorb
ScoreFirst: chooses the tile most likely to contain a 2 or a 3 tile
CutoffN: Begins as ScoreFirst and changes to MinRisk after N iterations
Here are their findings1:

As you can see, BOGOFlip has a (expected) 0% success rate, and all three other algorithms have ~62% success rate. That’s pretty good! But is that optimal?
Preliminary Work
Let’s see if we can come up with a better algorithm, or indeed any algorithm that isn’t one of those four. In order to test an algorithm, we need a way to play looooots of games, and I don’t particularly want to play 500 games of Voltorb Flip by hand. Not today, anyway.
So let’s build a Voltorb Flip simulator in Python. Github Repository Available Here2. (It’s very poorly documented at the moment, so beware!)
First, we need some data on board configurations. To generate a faithful simulation of Voltorb Flip, we need to know the probability distribution for each tile. What is the chance an individual tile is a 2, 3, or Voltorb? Fortunately, Bulbapedia3 comes to the rescue.
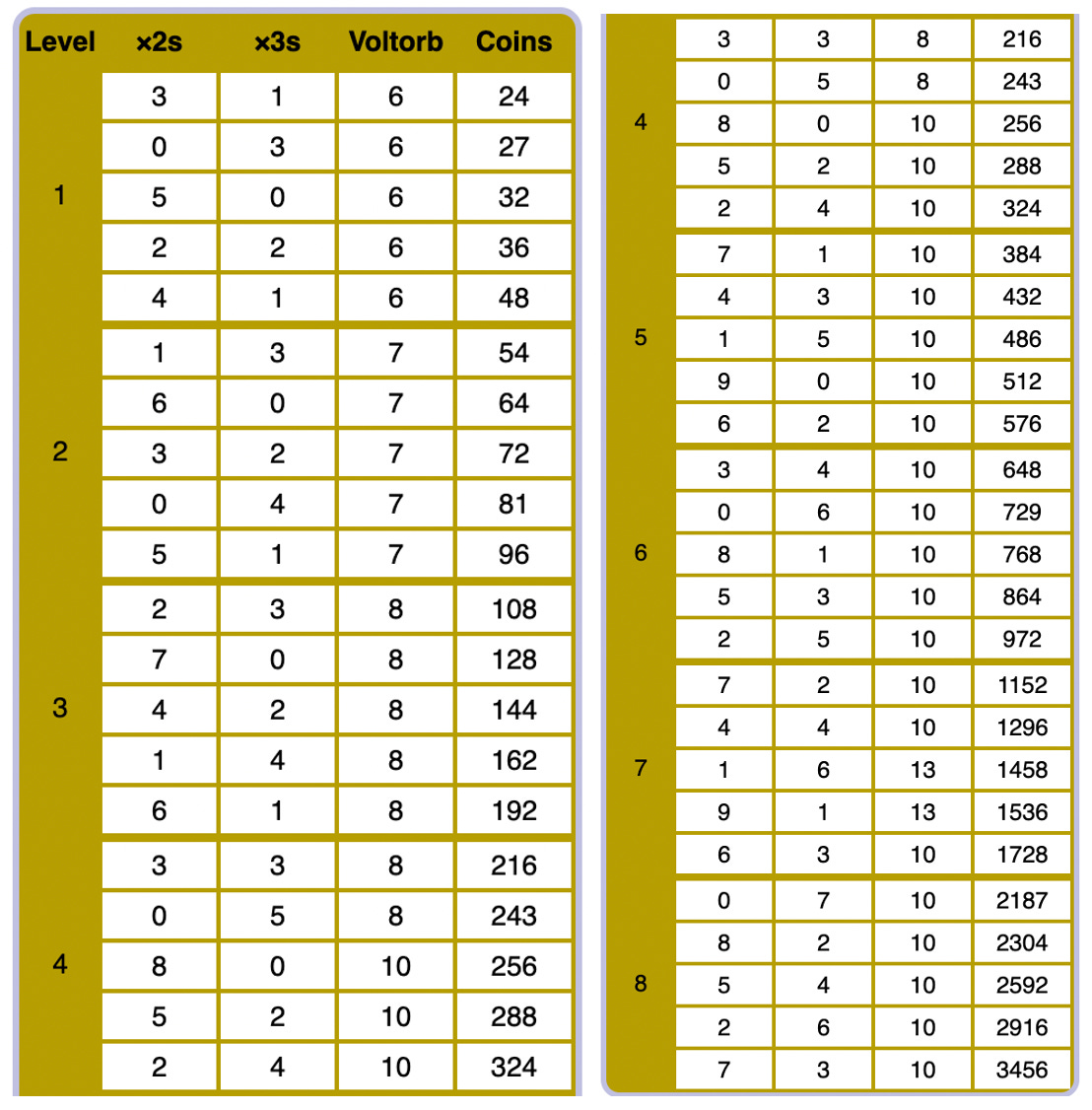
For our purposes, let’s just convert these tables to probabilities, and, for extra fun, let’s choose level 8 difficulty. Here’s the averaged probabilities for the possible level 8 boards.
Level 8:
P(1) = 0.248 → 24.8%
P(2) = 0.176 → 17.6%
P(3) = 0.176 → 17.6%
P(V) = 0.4 → 40%

We’ll just create a class that contains a 5x5 NumPy array for our tiles, and draw the value of each tile from a probability distribution defined by the Level 8 probabilities. Voltorbs can be represented by 0s.
Then, we’ll take the sum of each row and column (each line), and count the number of zeros in each line. This will give us the “characteristic statistics” of the board: the row and column sums, and row/column Voltorbs. We’ll call this the “game board.”

Now, to implement an algorithm for guessing, we need a way of labeling known information and eliminating exhausted lines. For that, let’s create another class that contains the remaining possibilities for each tile. Because I suck at code, I’m just going to make a 5x5 array containing the string ‘0123’ and remove the corresponding digit when I eliminate that possibility. I’ll call it a “label board.”

Now, we need some methods for updating our label board by applying our two and a half rules, and pulling the correct answers from the game board. A few lines of code later, and a bunch more randomly generated boards…

Okay! We’re all ready for trying out guessing algorithms.
A Heuristic Algorithm
Let’s see if we can think our way to a good heuristic algorithm. Consider the following game board:

We want to simultaneously maximize our chances of flipping a 2 or a 3 tile, and minimize our chances of hitting a Voltorb. Recall our definition of the “reward” remaining in each line:
R = S - 5 - yR - 2 zR
If we calculate R for each row, we find: (1, 2, 1, 0, 1)
For each column, we find: (0, 0, 2, 1, 3)
Looking at the reward for each line, it seems like row 2 and column 5 are our best bets. A first pass at a heuristic would choose tile (2, 5). Let’s also take the outer product of our two R vectors to create a combined “reward product” for each element.

But we also want to minimize our chances of hitting a Voltorb. Can we take that into account as well?
Why don’t we create a Figure of Merit (F) by dividing the remaining reward R of each line by the number of Voltorbs V in each line? This gives us a bunch of divide-by-zeros, so let’s actually divide by 1+V:
F = R / (1 + V)
This will be our figure of merit for each line.
For our example board:
row F: (1, 2, 1, 0, 1) / (2, 2, 3, 2, 3) = (0.5, 1, 0.33, 0, 0.33)
col F: (0, 0, 2, 1, 3) / (3, 1, 3, 3, 2) = (0, 0, 0.66, 0.33, 1.5)
where / is an elementwise division operation in the above expressions.
This heuristic also says to choose tile (2, 5). That’s good, because our figure of merit should match our intuition. Let’s take the outer product of these two vectors to construct our Figure of Merit Board.
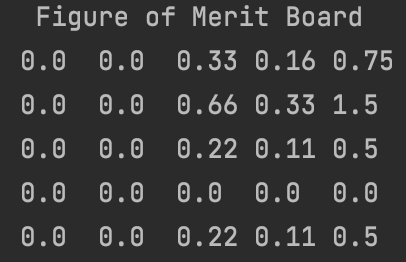
This looks pretty good! In our game board, column 1 and row 4 are eliminated by the 5-sum rule, and column 2 is completely flipped over already. This is reflected in our Figure of Merit Board. The intuitively “best” tile has the highest FoM, and the tiles appear to be ranked reasonably.
Our new heuristic algorithm will flip over the tile with the highest figure of merit, re-check the board for remaining reward R, re-calculate the new FoM Board, and repeat. Let’s try it out on our example board!

Well darn. It was a Voltorb. Can’t win ‘em all, I guess.
Of course, a single trial isn’t a fair test of our algorithm. Let’s do 10,000 trials and calculate the success rate. This type of simulation is known as a Monte Carlo method, where instead of analytically solving a problem, we simulate a sufficient number of randomized cases and assume the outcome is representative of the general problem. This method is widely applied in math, physics and many other fields of study, and is my personal favorite method of estimating the solution to difficult problems. Here’s an article on using Monte Carlo methods to do more useful things than play Voltorb Flip, like calculate pi.
But I digress. Let’s simulate 10,000 games of Voltorb Flip.
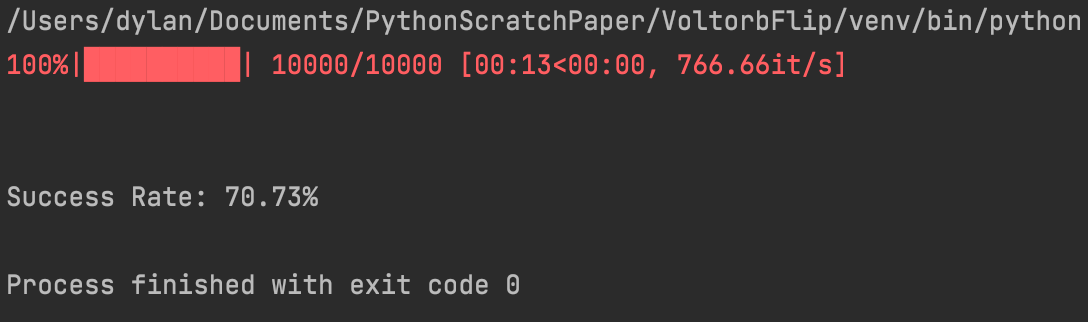
71%. Not bad at all! Just using this simple heuristic, we win 71% of boards on the highest difficulty setting! Let’s try it with Level 2 boards, the same as Jaff et al. used to evaluate their algorithms. Another side note: I’m using the package tqdm to create lovely dynamic progress bars for long-running functions. I can’t recommend it enough, especially for people (like me) that do lots of Monte Carlo simulations.
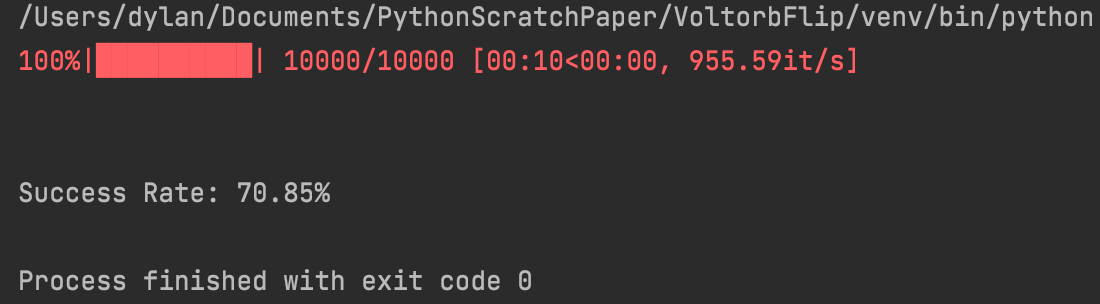
71% again. Hmm. It seems that this algorithm isn’t very sensitive to difficulty level. Let’s try Level 4 boards.
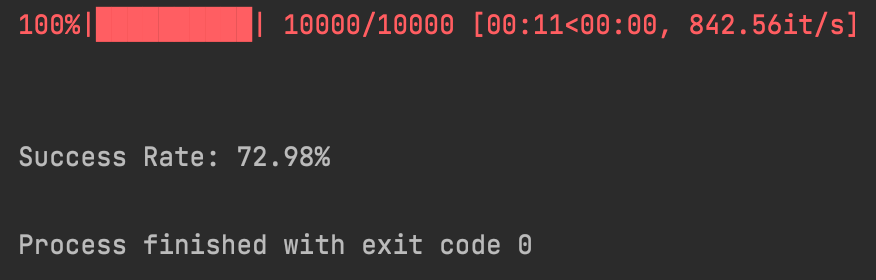
73%. That’s actually a bit better. I wonder whether the difficulty level actually means anything? 10,000 trials should be sufficient to average out lots of the inherent randomness of Monte Carlo simulations, and our algorithm doesn’t seem to perform meaningfully differently on high vs. low difficulty levels. Very odd, and possibly meriting further study.
Regardless, our algorithm is great! It seems to be a full 9 percentage points better than the best algorithm studied by Jaff et al. in their paper. Let’s try a few more figures of merit. Our initial guess, where we simply construct the Figure of Merit board from R, instead of R/(1+V):

69%. It’s a bit worse, maybe. Could be noise in the simulation. It also probably means we should test our algorithm against the exact same boards that Jaff et al. used to make a fair comparison. Instead, let’s test to see if our code is working by giving it a completely wrong figure of merit.

17%. Oh yeah, the algorithm is way worse if I use an intentionally meaningless figure of merit.
Let’s see how many difficulty levels we can get through in Pokemon Reborn using our algorithm.
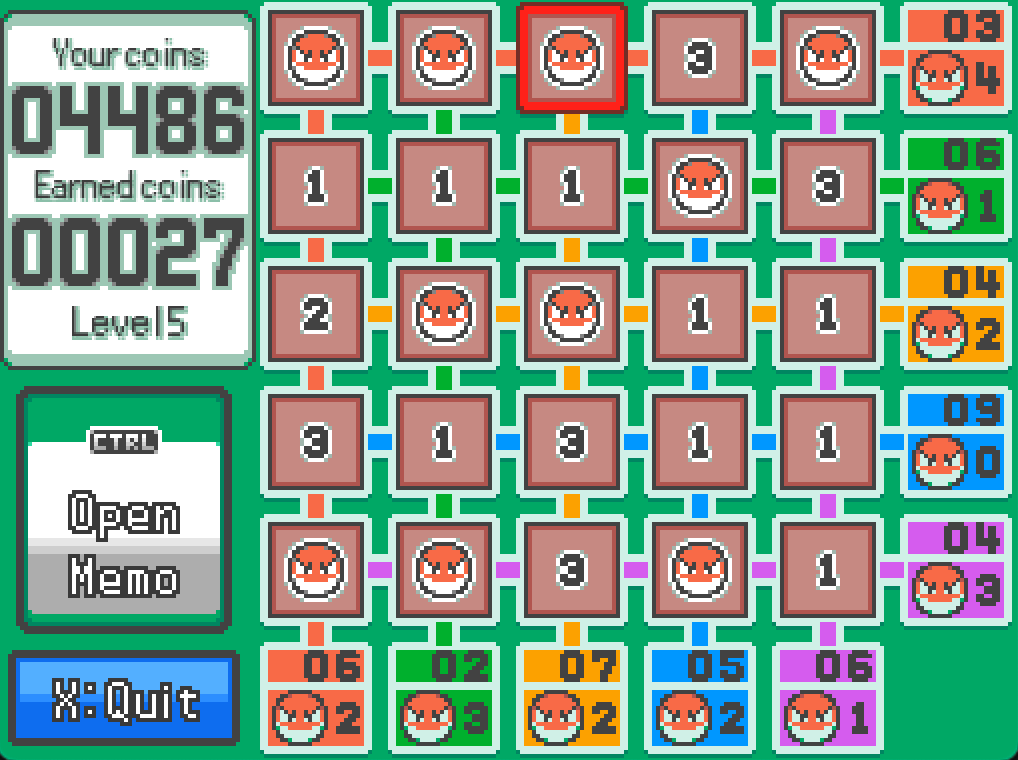
On average, we advance pretty rapidly, and I got to level 5 without too much trouble. However, it is really annoying having to manually enter the game statistics into python. I wonder if we can do this better?

Of course we can, using the magic of Optical Character Recognition! Stay tuned for Part 3 (and Part 2.5) of this mildly exciting series on Voltorb Flip, in which I build an OCR engine that automatically reads the board state from Pokemon Reborn into our heuristic guessing algorithm, saving me multiple seconds of work at the cost of many hours of coding.
E Jaff, L Bohrer. Voltorb Flip Algorithm Analysis. 2021. https://evinjaff.github.io/papers/VoltorbFlip.pdf.
https://github.com/Sparkplug94/VoltorbFlip
https://bulbapedia.bulbagarden.net/wiki/Voltorb_Flip